4 min read
kdb+: Attributes for Beginners’
kdb+ is known for its ability to store, retrieve and process large data volumes at high-speed. One of the many things that make this possible is Attributes – descriptors that can be applied to lists. These descriptors allow the q interpreter to perform optimizations “under-the-hood” that can drastically increase lookup speeds when used effectively.
This blog will cover the Attributes used in kdb+, what each attribute tells the q interpreter, and how a given attribute could be used to increase performance.
Sorted (`s#)
When the `s# attribute is applied to a list it tells the interpreter that the elements of that list are sorted in ascending order. This allows q to perform a binary search on the list by default, drastically reducing lookup times.
//create sorted list of 10000000 rows
q)names:`Alan`John`Muhammad`Mary`Joseph`Sean`Patrick`William`Katherine
q)n:10000000;
q)employee:([] id:.Q.dd'[n?names;til n]; salary:20000+n?50000);
q)employee
id salary
-------------------
William.0 29809
Mary.1 44125
Katherine.2 31158
Sean.3 68322
Katherine.4 25272
..
q)meta employee
c | t f a
------| -----
id | s
salary| j
// query top earners without `s# applied (linear search)
q)t select from employee where salary>65000
126 //(t=126) query ran in 126 milliseconds
// sort employees on salary
q)`salary xasc `employee //this automatically applies `s on sort column
`employee
// query top earners with `s# applied (binary search)
q)t select from employee where salary>65000
31 //(t=31) query ran in 31 milliseconds
Binary searching is an efficient search algorithm on sorted lists. It works by sampling the midpoint of a list, splitting it in two. Depending on the result it picks one of the two resulting lists to sample. This process is repeated until the list is narrowed down to an individual location.
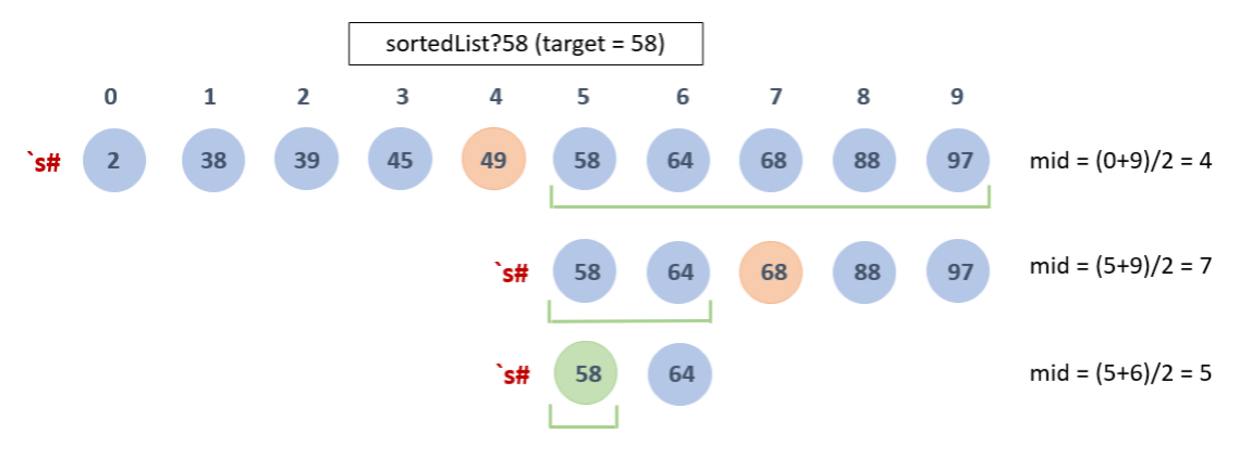
Many people have described a binary search algorithm more eloquently than I ever could so here’s a good article I found.
Unique (`u#)
Applying the `u# attribute to a list indicates that all the elements in the list are unique. One of the optimizations the unique attribute allows is the interpreter can break-out from some functions early e.g. the ‘distinct’ function.
The real power of `u# comes from constant time look ups on unique list elements. To achieve this q creates a hash-table in the background – which takes up some of the memory available to your Q process, this may become a considering factor in applying `u# depending on list size/kdb+ setup.
Using our previous ‘employee’ table, let’s look at the performance gains when using the `u# attribute.
//select last employee id from employees table
q)t select from employee where id=`Patrick.4326549
28 //(t=28) query ran in 28 milliseconds
q)t select distinct id from employee
256 //(t=256) query ran in 256 milliseconds
//apply the unique attribute to the id column
q)employee:update id:`u#id from employee;
//Same queries With `u# applied
q)t select from employee where id=`Patrick.4326549
0 //(t=0) query ran in less than 0 milliseconds
q)t select distinct id from employee
0 //(t=0) query ran in less than 0 milliseconds [distinct early exit]
Although hash-tables are slightly beyond the scope of this blog, I found it very interesting to learn more about how database indexing with hash-tables is working in this given scenario. Anyone interested in some further reading on this I would recommend reading here.
Parted (`p#)
Application of the `p# attribute on a list tells the interpreter that all commonly occurring values are positioned adjacent in a contiguous block I.e. all common values sit beside each other.
q)contiguousList:`SNY`SNY`IBM`IBM`IBM`IBM`APPL`APPL`APPL`VOD`VOD`VOD
When the `p# attribute is applied q creates a dictionary storing the position of the first occurrence of each block of values, therefore q knows the exact range of addresses to look at when retrieving this data.
q)first each group contiguousList
SNY | 0
IBM | 2
APPL| 6
VOD | 9
Anyone who has worked with kdb+ will be aware that a table’s ‘sym’ column generally has the `p# attribute applied on disk and the `g# in memory (see `g# below)– why is this the case?
It’s typical that when querying a securities database most queries will filter on a particular asset first i.e., ‘APPL’ or ‘GBPUSD’. By applying the `p# attribute to the column identifying an asset (‘sym’); assets are stored in a contiguous block on disk. Therefore, when q needs to pull this data into memory the range of indices to retrieve is known in advance because of the `p#, speeding up any on-disk lookups.
q)n:100000000;
q)syms:`VOD`GOOG`IMB`MSFT`AMZN;
q)trade:([]time:n?.z.t;sym:n?syms;price:n?10000f); //create a trade table
q)`:2020.12.01/trade/ set .Q.en[`:.;trade]; //save table in hdb
q)l . //reload hdb
q)meta trade //meta info shows no `p#
c | t f a
-----| -----
date | d
time | t
sym | s
price| f
q)t select from trade where date=2020.12.01,sym=`GOOG;
1790 //(t = 1790) query took 1790 milliseconds
//apply `p# to on-disk table
q)@[`sym xasc .Q.par[`:.;2020.12.01;`trade];`sym;`p#];
q)meta trade //meta info shows `p# applied to sym
c | t f a
-----| -----
date | d
time | t
sym | s p
price| f
q)t select from trade where date=2020.12.01,sym=`GOOG;
274 //(t = 274) query took 274 milliseconds