8 min read
The AI hallucination factor

How Large Language Models sometimes lose the plot
AI Large Language Models (LLMs), such as GPT-4 or Claude, have revolutionised how we interact with artificial intelligence by generating remarkably coherent and human-like text. However, one of the most intriguing and challenging behaviours of these models is their tendency to “hallucinate”.
What is an AI hallucination?
An AI hallucination is when an AI model produces an answer that sounds correct but it’s actually false – it’s as if the AI is “making things up”.
Think of it like a child guessing an answer or predictive text on your phone – neither truly understands the answer, but both generate responses based on patterns they’ve learned. Similarly, an AI generates a response based on patterns it has learned, but it doesn’t truly “understand” the answer like a human would.
As an example, if you ask an AI for a famous quote and it confidently provides you with something that sounds plausible but was never actually said, that’s an AI hallucination.
Now that you’ve got the basics, let’s dive into a more detailed explanation of why AI hallucinations occur.
Why do hallucinations occur?
Understanding why AI hallucinations occur requires a closer look into how AI models like GPT-4 or Claude are built, trained, and how they generate text. Unlike humans, who learn from experiences, AI models learn by consuming vast amounts of text data and identifying patterns. When asked a question, they don’t retrieve facts from a database. Instead, they generate answers based on what they predict is the most statistically likely response, drawing from patterns they’ve learned during training.
But here’s the catch: AI doesn’t “understand” what it’s saying. It doesn’t have context, memory, or awareness. It operates purely on statistical likelihoods, and when it encounters gaps or ambiguous information, it tries to “fill in the blanks” with its best guess. This is where hallucinations often come into play.
Probabilities, not facts
At the core of an LLM’s behaviour is its reliance on probabilities. When an LLM generates a response, it does so by predicting the next word in a sentence based on the patterns it has seen during training. It doesn’t “know” facts but instead calculates the likelihood of different possible words appearing next.
For example, if you ask, “What’s the capital of France?” the model has likely seen this question (or ones like it) many times during its training, so it confidently answers, “Paris.” But what if you ask a more obscure question, such as, “Who was the mayor of a small town in 1910?” The model might still generate a response, even though it doesn’t have enough data to answer accurately.
Gaps in data
LLMs are trained on vast datasets, but no dataset is perfect. There are always gaps in the information that the AI has seen, especially on niche or highly specific topics. Because the world is constantly changing and no AI model can be trained on all available data, hallucinations become more common when the model encounters unfamiliar topics or scenarios.
For instance, if you ask about a recent event that occurred after the AI’s training data cutoff, it may attempt to generate an answer anyway. Without access to up-to-date information, the model will guess based on the patterns it has seen before, often resulting in hallucinations.
Filling in the blanks
Another reason AI hallucinations occur is that LLMs are designed to generate complete responses, even when they don’t have all the information. Humans are good at dealing with uncertainty – we often admit when we don’t know something. LLMs, on the other hand, are not programmed to express doubt. When they encounter ambiguity or gaps in their knowledge, they fill in the blanks by generating what they consider the most statistically likely response.
For example, if an AI is asked about an obscure scientific concept, it might not have a clear answer. But rather than admitting its uncertainty, it will often generate a response based on loosely related information from its training.
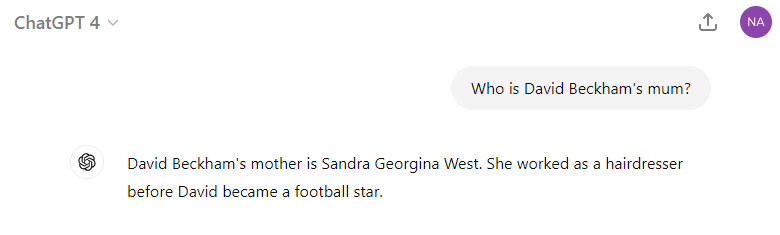

If you’re curious about the deeper mechanics behind AI hallucinations, let’s explore the technical side. We’ll look at how LLMs are built, how they generate text, and why they sometimes go wrong.
Attention, but not accuracy
At the heart of most modern LLMs is a model design called the transformer architecture. The transformer architecture uses a mechanism called self-attention to process input text. This mechanism allows the model to assign importance (or attention) to different parts of the input when predicting the next word in a sentence. Essentially, it helps the model figure out which words are most relevant to generating a coherent response.
For example, in the sentence “The dog chased the cat,” the model pays more attention to the relationship between “dog” and “chased” rather than to the less informative word “the.” Self-attention helps the model focus on the key elements of the input, improving the quality of the generated text.
However, while attention mechanisms are effective for generating coherent text, they don’t ensure factual accuracy. The model might focus on elements of the input that lead to a response that sounds credible but is entirely incorrect. This is particularly true when the input spans topics or concepts the model hasn’t been explicitly trained on, causing it to interpolate or extrapolate from irrelevant data.
Word choice by probability
At the core of an LLM is its probabilistic nature. Language models assign probabilities to every possible next token based on the patterns it has seen in training data. This is done using a softmax function, which converts raw scores (logits) into probabilities that sum to one. The model then selects the token with the highest probability to generate the next word in the sequence.
When an AI model is uncertain about the next token – because it lacks specific training data on the topic – the distribution of probabilities may become more diffuse, indicating higher entropy. In these cases, the model is forced to select a token from a low-confidence distribution. As a result, the generated response may appear confident but is underpinned by weak probabilities, leading to factual inaccuracies or hallucinations.
For instance, when the model is prompted with a niche or highly specialised topic it hasn’t encountered often during training, the probability distribution it generates may be based on very weak associations. This can result in an output that, while grammatically correct, is factually wrong.
Mixed-up knowledge
LLMs don’t store knowledge in the same way a database would. Instead, they represent all information in a high-dimensional latent space. In latent space, words, phrases, and concepts are encoded as vectors – numerical representations that capture relationships between ideas. When an AI model generates text, it manipulates these vectors to produce coherent language.
However, this method of encoding knowledge is far from perfect. Hallucinations can arise when the model pulls vectors from disparate parts of latent space, leading to erroneous combinations of concepts. For example, if an AI is asked to generate a description of a historical event, it may combine vectors representing unrelated aspects of history, resulting in a fabricated but coherent-sounding response.
This problem is further exacerbated when the input prompts the model to delve into areas where it has limited training data. The vectors it retrieves might not accurately reflect the true relationships between ideas, leading to responses that are logical in structure but flawed in content.
Overfitting to bad data
Another technical cause of hallucinations is overfitting, a phenomenon where the model becomes overly reliant on specific patterns in its training data. If the training data contains biases or inaccuracies, the model may reproduce these errors with unwarranted confidence. Overfitting can lead to the model generating overly specific or factually incorrect information when faced with unfamiliar input, as it tries to apply previously learned but irrelevant patterns.
In addition, data biases in the training corpus can introduce systemic inaccuracies. For instance, if the training data over-represents certain perspectives or omits key facts, the model may hallucinate responses based on incomplete or skewed knowledge. This is particularly problematic in sensitive areas such as medical or legal information, where hallucinations could have real-world consequences.
Feedback helps, but not enough
To help LLMs become more accurate, researchers often employ Reinforcement Learning from Human Feedback (RLHF). In this process, human evaluators review and rate the model’s outputs, providing feedback on which responses are accurate and which are not. This feedback helps the model adjust its internal parameters to reduce the likelihood of hallucinations in the future.
While RLHF can significantly improve the model’s ability to avoid hallucinations, it’s not a perfect solution. Even with reinforcement learning, LLMs remain probabilistic and can still generate incorrect information when they encounter unfamiliar or uncertain input. The model may improve its “averaged” performance, but edge cases – rare or niche scenarios – will still pose a problem, particularly if they weren’t well-covered during training or feedback loops.
Limitations of LLMs and future direction
AI hallucinations occur due to the inherent limitations of how LLMs function. These models rely on probabilistic predictions, latent vector spaces, and vast amounts of training data to generate responses. While these methods are powerful for producing coherent and human-like text, they also leave room for errors, especially when the model faces unfamiliar or ambiguous situations.
Hallucinations are an inevitable byproduct of these systems, and while techniques like RLHF and the integration of knowledge bases can help, they don’t fully solve the problem. As AI research progresses, future innovations may introduce models that are better at verifying information and dealing with uncertainty, reducing the frequency of hallucinations.
For now, it’s crucial to understand that while LLMs are extraordinary tools, they aren’t perfect. Knowing their strengths and limitations helps users engage with these technologies more responsibly, leveraging their capabilities while being aware of their potential to hallucinate.
About the author
Nathan Marlor leads the development and implementation of data and AI strategies at Version 1, driving innovation and business value. With experience at a leading Global Integrator and Thales, he leveraged ML and AI in several digital products, including solutions for capital markets, logistics optimisation, predictive maintenance, and quantum computing. Nathan has a passion for simplifying concepts, focussing on addressing real-world challenges to support businesses in harnessing data and AI for growth and for good.