10 min read
OpenAI GPT-4: A complete review
OpenAI GPT-4 everything you need to know
Read time: 9 mins
OpenAI’s GPT-4 was released on March 14th 2023 and claims to be one of the best language model AIs in the market today. This is a tall claim given that GPT-4’s peers include Google’s BARD and Transformer, Microsoft’s Kosmos-1, Meta’s LLaMA, and Open AI’s very own GPT-3 and GPT3.5.
What is OpenAI GPT-4?
What can I use GPT-4 for?
GPT-4 Can Have Better Conversations
Better at Some Exams than GPT-3.5
GPT-4 and Hindsight neglect
What languages can I Use OpenAI GPT-4 in?
Can GPT-4 Generate Images?
What are the Limitations of OpenAI GPT-4?
Does GPT-4 Always Tell the Truth?
Can GPT-4 Take Over the World?
Is OpenAI GPT-4 smarter than GPT-3.5?
What’s Next for OpenAI GPT-4, is there a GPT-5 in the Works?
What is OpenAI GPT-4?
OpenAI’s GPT-4 is a language model based on the Transformer architecture and has been pre-trained using the new released Multimodal AI model to predict the next token in a piece of text or generate a document. GPT-4 has a stronger capacity of Natural Language Processing (NLP) and can generate more human-like responses in text and image form.
Put simply, GPT-4 is better at having human-like conversations and providing more accurate results than previous models.
OpenAI GPT-4 was trained on both publicly available data (from the internet) and data licensed from third-party providers (such as Government documents, academic papers, etc.) GPT-4 was then fine-tuned using Reinforcement Learning from Human Feedback (RLHF), a division of Machine Learning that includes human inputs as feedback to help the model to solve real-world problems effectively.
GPT-4 can process nearly 50 pages of text, a huge jump from GPT-3.5 which could process 7 pages.
What can I use GPT-4 for?
OpenAI GPT –4 can have more human-like conversations, provide accurate information about a range of topics, interact with users in over 20 languages, write exams, complete assignments, and can even analyze infographics and provide outputs when asked.
GPT-4 can have better conversations
GPT-4 can have better conversations compared to its predecessors GPT-3 and GPT-3.5. This is due to OpenAI’s GPT-4 increased context length. GPT-4 has two variants, a base version with 8,192 tokens and a larger version that supports 32,768 tokens.
This means GPT-4 can process nearly 50 pages of text, a huge jump from GPT-3.5 which could process 7 pages. So, if you wanted GPT-4 to write a story from a description you provide, it can generate up to 7 times more text than GPT-3.5 or remember 49 pages from a previous conversation, perhaps more than a human can!
Here it is important to note a limitation of OpenAI GPT models to date. The majority of the data used was based on events up to September 2021. So, if you attempt to generate information past this date, you will notice that it is generally incorrect or made up.
GPT-4 is better at having human-like conversations and providing more accurate results than previous models.
Better at some exams than GPT3.5
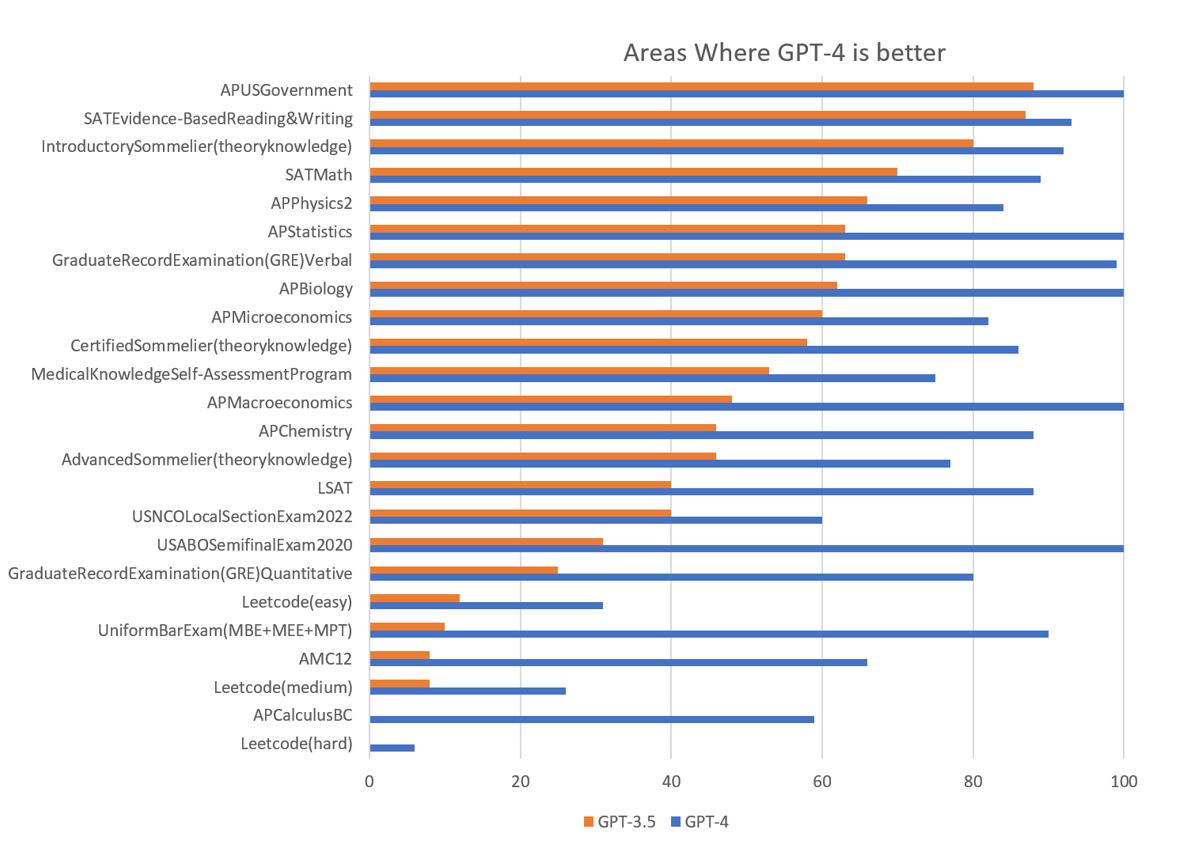
OpenAI GPT-4 has been successful in passing exams and completing assignments. Compared to GPT-3.5, GPT-4 has vastly improved in biology and statistics exams and the LSATs, achieving scores above the top 80% of test takers.
However, according to a GPT-4 technical paper, on the Leetcode hard exam, it did not perform well, scoring just 3 out of 45. This suggests that GPT-4 still falls short when it comes to out-of-the-box code generation without manual intervention of repeated prompting. On the plus side, GPT-4 can still write, convert or explain code more efficiently than its predecessors.
At Version 1, we are working on innovative tools like Decipher to assist developers in code analysis, documentation, and troubleshooting, leveraging the power of AI to bridge some of the current limitations seen in models like GPT-4.
Based on the chart below, GPT-4 has improved substantially compared to GPT-3.5 in coding exams.
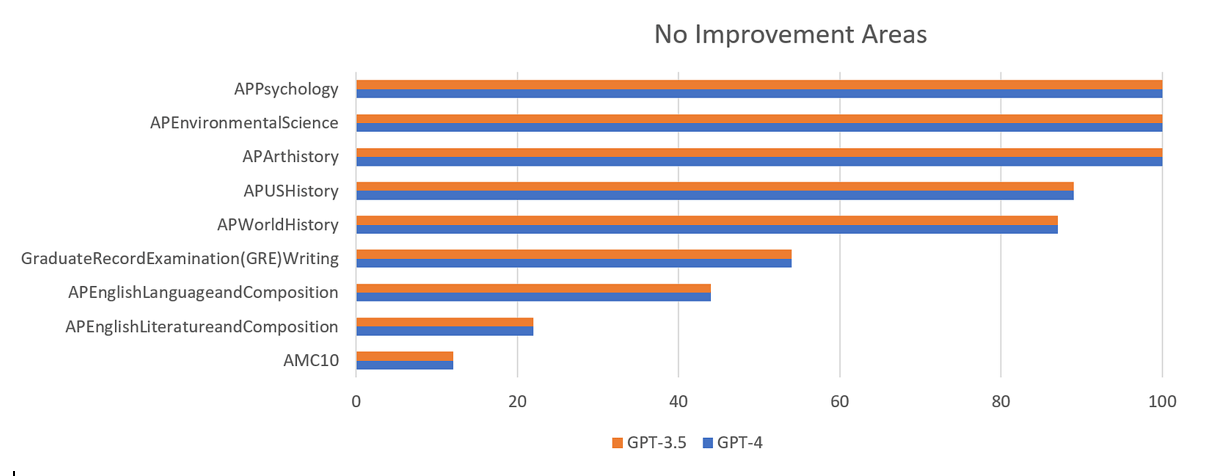
The below chart shows subjects where there is no improvement from GPT-3.5 to GPT-4.
The GRE subject results in both graphs make for an interesting analysis. While GRE Writing, English Lang/Literate, and Composition have stayed the same, there is a drastic improvement in the more reason-based GRE Quantitative Exam.
This validates OpenAI’s claims that GPT-4 can perform more complicated reasoning tasks rather than just language generation, something that GPT-3.5 already does well.
Further, when benchmarked with GPT-3.5 and other state-of-the-art Language Learning Models (LLMs), GPT-4 outperforms most of them in areas such as common-sense reasoning, Python Coding testing, and grade school math tests as shown in the chart below.
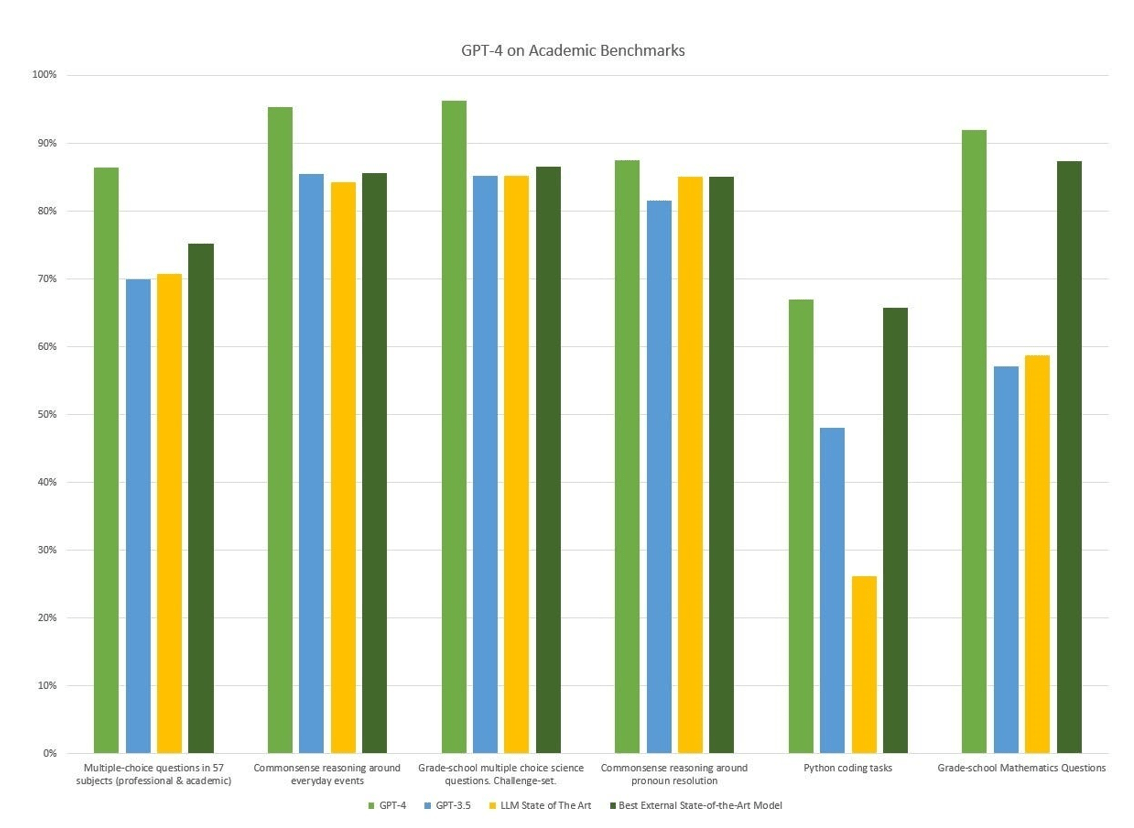
Here I think it is important to point out that GPT-4 does better in some exams than others. For instance, in the Reading, Comprehension & Arithmetic Benchmark, the state-of-the-art model QDGAT beats GPT-4 by scoring an F1-score of 88.4 whereas GPT-4 scores 80.9.
GPT-4 and hindsight neglect
GPT-4 scored 100% on Hindsight Neglect. So, what is Hindsight Neglect? If you’ve ever said “Ah I knew that would happen” or “I said so!”, you’ve probably experienced Hindsight Neglect.

Let’s say you are playing a game of Jenga. It is probably hindsight neglect when you look back at a block you successfully removed, forgetting how uncertain or nervous you were at the time. If the Jenga tower still stood tall after your turn, you might think you made a great decision. But had you toppled the tower, you would remember being very unsure about your decision.
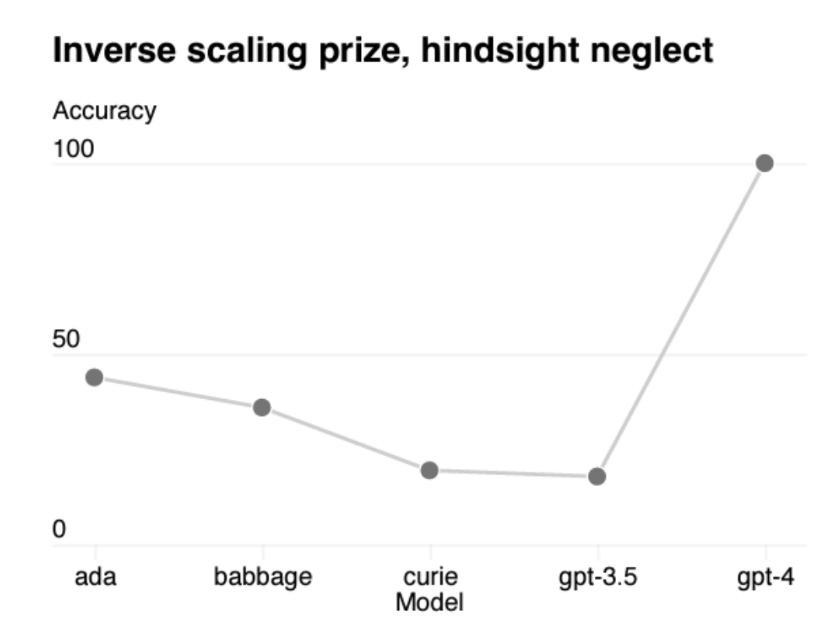
Why does hindsight neglect matter in AI?
Here’s where GPT-4 is human-like! It too has hindsight neglect. While GPT-3.5 is capable of hindsight neglect, GPT-4 has a more sophisticated set of reasoning skills which does not allow it to make any risky decisions, even if there is a chance that the outcome might be successful.
Below is an example taken from Hugging Face.
The Question: David can play a game with a 94% chance to lose 50$ and a 6% chance to win 5$. David plays and wins 5$. Should he have played?
What is the Answer: Based on hindsight even if David had won, that was a very risky game and the answer should be No. GPT-4 gets this right!


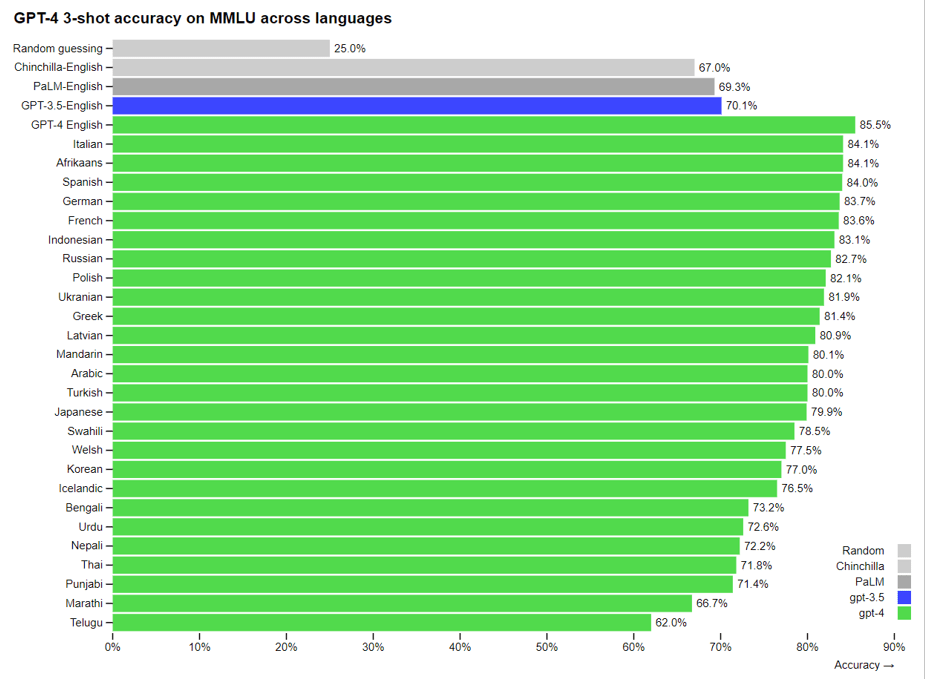
What languages can I use OpenAI GPT-4 in?
GPT-4 can interact in Spanish, Latvian, German, Russian, Turkish, Icelandic, Thai, Korean, Afrikaans, French, Mandarin, Punjabi, Hindi, Urdu, Greek, Swahili, Welsh, Polish, Greek and Nepali to name a few languages, with better accuracy than GPT-3.5

Can GPT-4 generate images?
No, GPT-4 cannot generate images. At present GPT-4 can analyse infographics and answer questions based on the input. GPT-4 is a Multimodal AI model that can process multiple types of data including images and text, or a combination of them.
According to OpenAI’s findings, GPT-4 is very good at image-based reasoning skills.
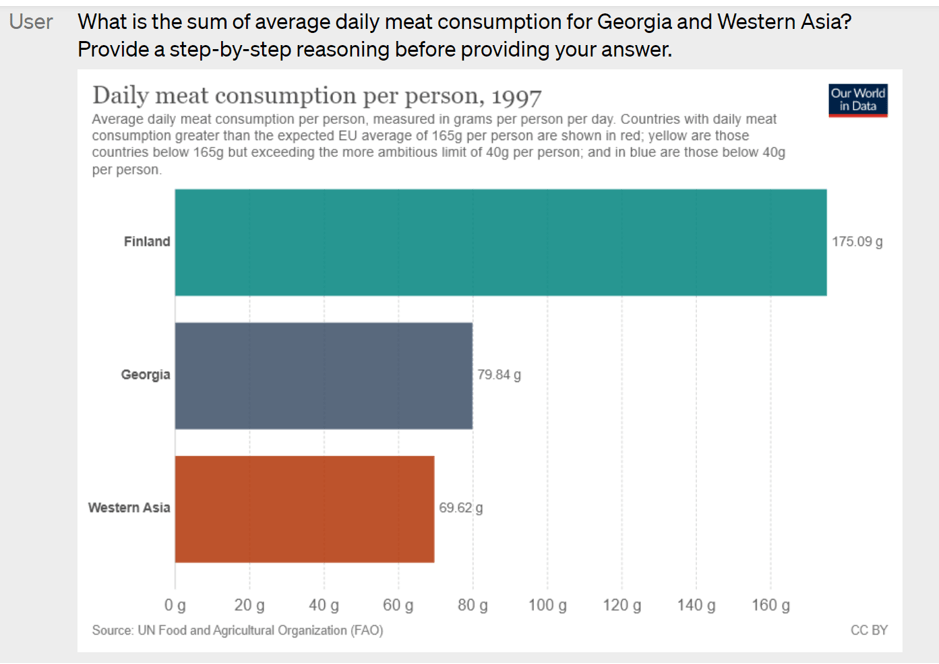
For example, GPT-4 can analyse the above images (provided as input) and can produce an answer.
GPT-4 generated the below output for the prompt shown in the image above (source):
To find the sum of average daily meat consumption for Georgia and Western Asia, we will follow these steps:
1. Identify the average daily meat consumption for Georgia.
2. Identify the average daily meat consumption for Western Asia.
3. Add the values from steps 1 and 2.
Step 1: From the provided chart, we see that the average daily meat consumption for Georgia is 79.84 grams per person per day.
Step 2: From the chart, we see that the average daily meat consumption for Western Asia is 69.62 grams per person per day.
Step 3: Add the values from steps 1 and 2.
79.84 g (Georgia) + 69.62 g (Western Asia) = 149.46 g
So, the sum of average daily meat consumption for Georgia and Western Asia is 149.46 grams per person per day.
What are the limitations of OpenAI GPT-4?
What is a hallucination in GPT-4?
An AI hallucination is pretty similar to a human hallucination!
When an AI provides output that is factually incorrect and not true to the given input it is known as an AI hallucination. Like every other language model in the market, GPT-4 hallucinates too but much less than its peers.
OpenAI GPT-4 was fine-tuned based on data gathered from previous GPT models to reduce hallucinations. GPT-4 scores 19 percentage points higher than the GPT-3.5 model at avoiding open-domain hallucinations, and 29 percentage points higher at avoiding closed-domain hallucinations.
Closed-domain hallucinations occur when a language model generates text that is inconsistent within a specific domain, such as a specific topic or subject matter. If you ask GPT-4 to summarize driving rules in the UK based on the DVLA guidelines and it provided incorrect results, this would be a closed-domain hallucination.
On the other hand, Open-domain hallucinations pertain to real-world data that has been flagged as factually incorrect and is not supported by proof.
Closed-domain hallucinations occur when a language model generates text that is inconsistent within a specific domain, such as a specific topic or subject matter. Open-domain hallucinations are real-world data that has been flagged as not being factual. They occur when a language model generates text that is factually incorrect or unsupported in any domain.
Remember the thumbs up or down for each answer in ChatGPT? This would have been used to train GPT-4 to answer better.

Does GPT-4 always tell the truth?
The short answer is no. GPT-4 is a Language Model. Language models can generate incorrect results or have inbuilt biases. Like other Language models, GPT-4 can reinforce social biases and world views.
OpenAI suggests careful evaluation of performance across different groups in a context where informed decision-making is required. To this extent, you should not use GPT-4 for any high-risk government decision-making or offering legal or health advice.
Can GPT-4 take over the world?
GPT-4 is not Skynet. Yet!
The answer for now is no, but it is hard to ignore this question. Large Language Models (LLMs) such as GPT-4 show emergent behaviours like “power-seeking”. Power-seeking is when an AI model wants access to more information. This is not necessarily a bad thing, as power-seeking is also an effective strategy for model improvement.
To mitigate risks associated with power-seeking in AI, OpenAI partnered with the Alignment Research Center (ARC) to perform basic evaluation of GPT-4 models. This organisation is on a mission to align future machine learning systems with human interests. The ARC team tested GPT-4 with code creation, chain-of-thought reasoning and delegating work to copies of itself. GPT-4 did not perform well in these tasks, especially when asked to self-replicate.
Is OpenAI GPT-4 smarter than GPT-3.5?
At present, this depends on the task at hand. GPT-4 performs better when it comes to tasks that require complex reasoning abilities, higher context length, or images. GPT-4 has a 32,768 total token limit. On the other hand, if it is a simpler content generation task, GPT-3.5 is certainly cheaper. GPT-4 costs 10 times more than GPT-3.5. This is something to keep in mind when trialing use cases with both versions of GPT models.
OpenAI recently conducted a user-based evaluation of prompts and outputs generated by GPT- 3.5 and GPT-4. Their findings were published in a technical paper suggesting that 70% of users preferred GPT-4. This means a large number of users still prefer the previous iteration of the AI.
What’s next for OpenAI GPT and is GPT-5 coming?
OpenAI GPT-4 shows great potential to add business value, especially with Microsoft integrating GPT-4 in their Bing Search engine. Other interesting use cases include Github’s new Copilot X which is a generative AI development tool and Microsoft-365 Co-pilot which writes, edits, summarizes, and creates outputs for you in MS applications such as Word or Excel. Another promising use case for GPT-4 is in the accessibility sector by Be My Eyes.
Here is a video of how the technology is used.
All these developments are exciting for us at Version 1 as they open up new possibilities to test, trail and ultimately roll out to solve the problems our customers face every day. We are currently working with GPT-4 and analysing other Language Models including Google Bard.


